A
AWS
December 22, 20251회
Amazon RDS for PostgreSQL에서 고성능 시계열 데이터 테이블 설계

간단 소개
Amazon RDS for PostgreSQL에서 시계열 데이터의 고성능 테이블 설계를 위해 데이터 타입, BRIN 인덱스, 네이티브 파티셔닝 및 pg_partman/pg_cron 활용 방안을 제시합니다.
AI Summary
Amazon RDS for PostgreSQL 시계열 데이터 최적화
- Amazon RDS for PostgreSQL은 기존 트랜잭션 데이터와 조인하거나 배치 처리 시 시계열 데이터 저장에 적합합니다.
- 시계열 데이터는 append-only 특성으로 크기가 지속 증가하며, PostgreSQL 10+ 네이티브 파티셔닝과 PostgreSQL 13 파티션 프루닝 개선으로 성능 저하를 완화합니다. 데이터 타입 및 인덱스 전략
- 데이터 타입은 값 범위를 고려하여 과도한 할당을 피해야 하며, 'double precision' 대신 'real' 사용으로 DB 크기 및 로드 시간을 개선할 수 있습니다.
- B-Tree 대신 **BRIN (Block Range Index)**을 활용하여 시계열 데이터의 시간 범위 쿼리 성능을 최적화하고 인덱스 크기를 크게 줄일 수 있습니다. 파티셔닝 관리 및 성능 향상
- 네이티브 파티셔닝은 활성 데이터셋 크기를 작게 유지하여 'full-page writes' 및 메모리 초과 문제를 해결합니다.
- pg_partman과 pg_cron 확장을 통해 시간(time) 열 기준 범위 파티셔닝을 자동화하여 데이터 수집 처리량을 안정적으로 유지하고 성능을 획기적으로 향상시킵니다.
Next Feeds

Coroutine Async 로 지도보기 API 성능 개선하기
여기어때는 지도보기 API의 8초 응답 시간을 Kotlin Coroutine Async와 동적 Window 분할로 2초로 단축, TPS를 7배 개선했다.
Coroutine AsyncAPI 성능 개선표준 상품 API병렬 처리동적 Window 분할
2025. 12. 22.
여기어때

전시 도메인에 Kotlin DSL적용하기
여기어때 전시개발팀이 복잡한 숙박 상품 전시 로직의 가독성 향상을 위해 Kotlin DSL을 도입한 경험과 장단점을 공유합니다.
Kotlin DSL전시 도메인백엔드가독성복잡도
2025. 12. 22.
여기어때

Strands Agents와 Amazon Bedrock AgentCore를 활용해 포스트잇 워크숍을 파워포인트로 정리하기
Strands Agents와 Amazon Bedrock AgentCore를 활용해 포스트잇 워크숍 결과를 파워포인트로 자동 정리하는 AI Agent 개발 및 배포 방법과 맥락 보강 기법을 소개합니다.
Strands AgentsAmazon Bedrock AgentCoreAI Agent포스트잇 워크숍파워포인트 자동화
2025. 12. 22.
AWS
![공통 Kafka 전환기 [Part 2. 공통 Kafka 전환 여정]](https://miro.medium.com/v2/resize:fit:1200/1*CBaBRoVYjmcQc4ZHPeS-eA.png)
공통 Kafka 전환기 [Part 2. 공통 Kafka 전환 여정]
여기어때는 MirrorMaker2를 활용하여 8개 도메인 Kafka 클러스터를 공통 Kafka로 성공적으로 통합하고 운영 효율성을 높였습니다.
KafkaMirrorMaker2클러스터 통합데이터 복제운영 효율성
2025. 12. 22.
여기어때
복잡한 검색 홈, 구조는 유연하게 화면은 부드럽게 개선하기
여기어때 앱 검색 홈의 복잡한 구조를 모듈 분리, SwiftUI 전환, 커스텀 페이지 전환으로 개선한 경험.
검색 홈모듈 분리SwiftUI페이지 전환단방향 데이터 흐름
2025. 12. 22.
여기어때
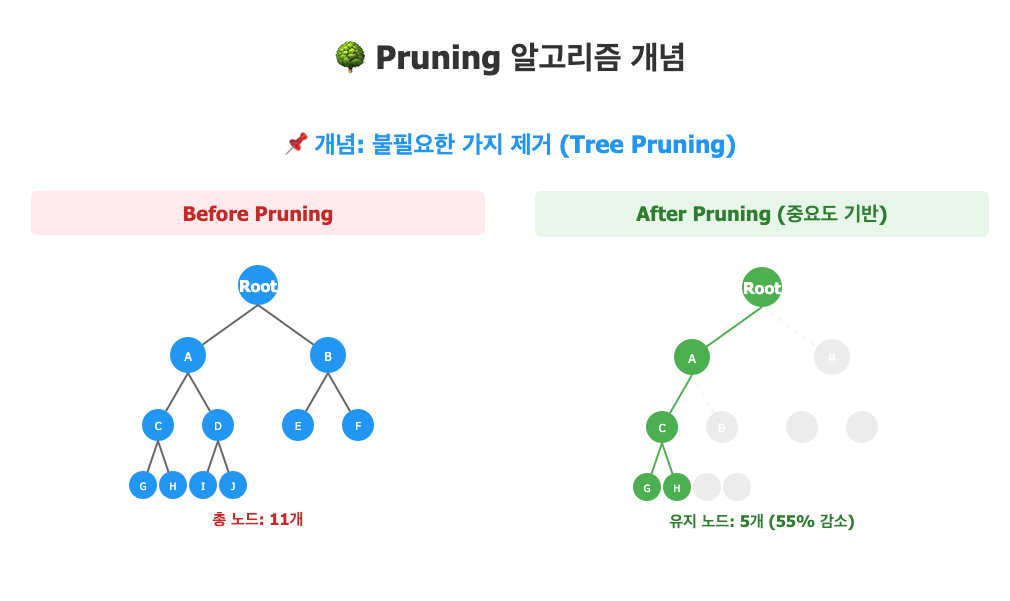
PLP 최저가 계산 최적화: 정말 모든 객실을 계산해야 할까?
여기어때 PLP 최저가 계산 시 모든 객실을 계산하는 비효율성을 Pruning 알고리즘으로 최적화하여 계산량을 70% 줄이고 성능을 개선한 경험을 공유합니다.
최저가PLPPruning최적화숙박
2025. 12. 22.
여기어때