- 이진 트리의 한계를 극복하기 위해 개발된 자가 균형 트리인 B-트리는 각 노드가 여러 개의 정렬된 키 자식을 가질 수 있어 대규모 데이터 검색 시 디스크 I/O를 크게 줄여줍니다. 🌳
- IP 주소처럼 공통 접두사를 가진 값들을 효율적으로 찾기 위한 Radix 트리는 단일 자식 노드를 부모와 병합하여 트리의 깊이를 줄여 검색 성능을 최적화합니다. 🌐
- 긴 문자열을 작은 조각으로 나누어 관리하는 트리 기반 데이터 구조인 Rope는 텍스트 편집기 등에서 대규모 문서의 효율적인 수정 및 조작을 가능하게 합니다. 🧵
- 특정 항목이 집합에 확실히 없는지 또는 있을 수도 있는지를 알려주는 확률적 데이터 구조인 Bloom 필터는 여러 해시 함수를 사용하여 빠른 멤버십 테스트를 제공하며 거짓 양성은 가능하지만 거짓 음성은 없습니다. 🕵️♀️
- 해시 충돌 해결 기법 중 하나인 Cuckoo 해싱은 각 키가 두 개 이상의 가능한 위치를 가지며, 자리가 차 있으면 기존 키를 "쫓아내고" 다른 위치에 재삽입하여 최악의 경우에도 상수 시간(O(1)) 검색 복잡도를 달성합니다. 🐦
- Code Rabbit은 개발자들이 코드 리뷰를 통해 버그를 조기에 발견하고 수정할 수 있도록 돕는 VS Code 확장 프로그램으로, 코드베이스의 전체 맥락을 이해하여 더 정확한 분석과 빠른 해결책을 제공합니다. 🐇
Recommanded Videos

Read everything about the contract and make sure they have a bigger following than you #memes
2025. 6. 24.
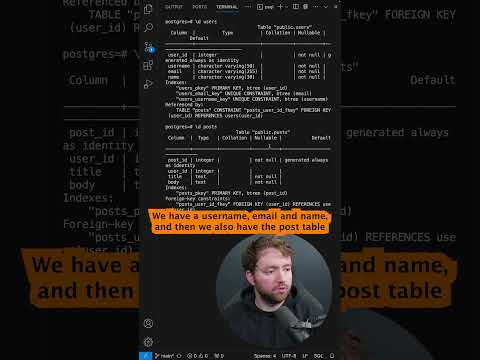
joins in sql
2024. 1. 16.
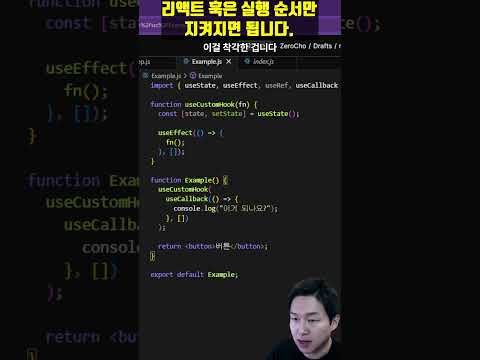
이 코드 리액트 훅 규칙 위반일까요?
2025. 2. 23.

커뮤니케이션이란 무엇인가? 어떻게 해야 효과적으로 협업을 할 수 있는가? (한빛미디어 의장 박태웅)
2021. 4. 27.

파이썬으로 코딩에이전트 만들기
2025. 11. 10.

🎥 Deep Dive into Flutter’s RenderObject Lifecycle! 🚀
2025. 2. 26.