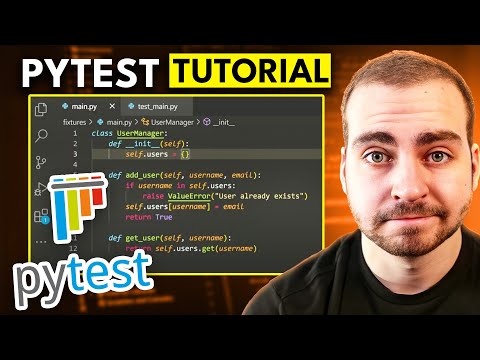
- GPT 5.2는 전문 작업 및 장기 실행 에이전트를 위한 혁신적인 최첨단 모델로, 추론, 코드 생성, 멀티모달 이해 및 도구 처리 능력이 향상되었습니다. 🚀
- 이 모델은 기본 GPT 5.2와 더 어려운 문제 해결에 특화된 GPT 5.2 Pro 두 가지 변형으로 제공됩니다. 🧠
- ARGI1 벤치마크에서 GPT 5.2 Pro는 90.5%의 최첨단 점수를 기록하며 1년 만에 390배의 효율성 향상을 보여주었습니다. 📈
- GDP Eva 벤치마크에서는 인간 전문가의 70.9% 작업을 능가하거나 일치하며, 1%의 비용으로 11배 빠른 결과물을 생성합니다. ⏱️
- 코딩 능력은 Gemini 3.0 Pro와 동등하거나 약간 우수하며, Swaybench Pro에서 55.6%를, Swaybench verified에서 80%를 달성하여 안정적인 패치 및 기능 구현을 가능하게 합니다. 💻
- 응답 오류율이 8.8%에서 6.2%로 감소했으며, 연구 및 글쓰기 정확도가 향상되었습니다. ✍️
- 256k 토큰까지의 긴 컨텍스트 테스트에서 거의 100%에 가까운 성능을 보이며, 대규모 보고서 및 프로젝트에서 회상 및 종합 능력을 향상시킵니다. 📚
- 환각 현상이 30~40% 감소하여 긴 컨텍스트 처리의 중요한 문제를 해결합니다. 🚫
- 시각 정확도는 Chexive에서 88.7%, Screenshot Pro에서 86.3%에 달하며, 차트 및 소프트웨어 화면을 더 적은 오류로 읽어냅니다. 👁️
- 도구 사용 능력은 Tow Telecom에서 98.7%, Tow Retail에서 82%를 기록하며, 데이터 풀링, 사례 해결, 문서 생성과 같은 다단계 워크플로우를 원활하게 처리합니다. 🛠️
- AIM 2025 (도구 없음) 벤치마크에서 수학 문제 해결에 100% 성공률을 달성하여 이전 모델 대비 엄청난 발전을 보여줍니다. 💯
- 애니메이션 랜딩 페이지, SVG 코드, 해양 시뮬레이션, 타이핑 게임, 브라우저 기반 OS 등 복잡하고 기능적인 결과물을 한 번에 생성하는 뛰어난 능력을 시연했습니다. 🎨
- 이미지에서 마더보드의 미세 부품을 정확하게 식별하고 주석을 달 수 있는 강력한 비전 기능을 갖추고 있습니다. 🔬
- 현재 100만 입력 토큰당 $1.75, 100만 출력 토큰당 $14로 책정된 세 번째로 비싼 모델입니다. 💰
- 400k 컨텍스트 창과 2025년 8월 31일의 지식 차단점을 가지며, 최대 128k 토큰을 출력할 수 있습니다. 🗓️
- 실제 작업에 탁월하며, 수학, 과학, 일반 지식 분야에서 다른 어떤 모델보다 우수하고, 거짓 정보를 제공할 가능성이 적습니다. ✨
- ChatGPT 구독(Plus, Pro, Business), Alamarina(무료), OpenRouter 또는 Kilo Code API를 통해 접근할 수 있습니다. 🔗
- 연말 이전에 코딩 전용 Codex 버전이 출시될 예정입니다. 🔜
Recommanded Videos