- LLM 성능은 입력 길이(컨텍스트)가 길어질수록 예측 불가능하게 저하되며, 이는 주요 모델에서 공통적으로 관찰된다. 📉
- 이 현상은 '컨텍스트 로트(Context Rot)'로 불리며, 모델이 긴 컨텍스트 내의 토큰을 안정적으로 처리하지 못하는 경향을 보인다. 🧠
- 기존 '건초 더미 속 바늘 찾기(Needle in a Haystack)'와 같은 단순 검색 벤치마크는 실제 의미론적 이해를 평가하기에 부족하다. 🔍
- 과제 복잡성을 유지한 채 입력 길이만 늘려도 성능 저하가 발생하며, 특히 유사하지만 잘못된 정보(distractors)가 있을 때 심화된다. 🧩
- 디스트랙터(유사 오정보)는 짧은 입력 길이에서도 성능을 크게 떨어뜨리며, GPT 모델이 특히 취약한 경향을 보인다. ⚠️
- 정보의 존재 여부뿐 아니라 정보가 제시되는 방식, 즉 '컨텍스트 엔지니어링'이 LLM 성능에 결정적인 영향을 미친다. 🏗️
- 클로드 모델(특히 Opus)이 다른 모델에 비해 상대적으로 긴 컨텍스트에서 더 나은 안정성을 보이지만, 여전히 성능 저하를 겪는다. 💪
- LLM의 진정한 능력을 평가하기 위해 단순 검색을 넘어선 더 정교한 벤치마크 개발이 필요하다. 📊
Recommanded Videos

Not everything should be a cast and not everything should be an interface #gamedeveloper #memes
2025. 7. 16.
Do something toward learning programming every day - even if it's just 10 minutes
2025. 11. 25.

Using Godot for mixed-reality livestreaming – badcop – GodotCon 2025
2025. 8. 15.

Stop Making This Mistake in Next.js
2024. 8. 4.

NVIDIA BUSTED Devin with DEEPSEEK R1!!!
2025. 2. 13.
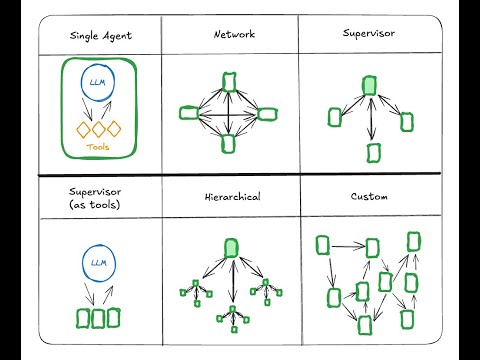
Conceptual Guide: Multi Agent Architectures
2024. 10. 16.