Loading...
Recommanded Videos

30대 초반 컴공 시작하면 취업이 가능할까요?
2024. 7. 31.

Once You See AI Agents This Way, You Can't Go Back
2026. 1. 7.

OpenAI GPT-4.1 First Tests and Impression: A Model For Developers?
2025. 4. 15.
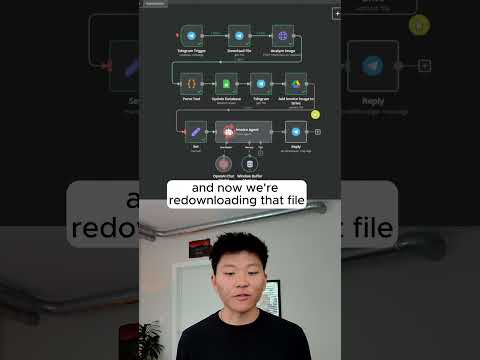
This Invoice Agent Analyzes Images in n8n #techtok #agentgpt #artificialintelligence #n8n
2024. 12. 5.
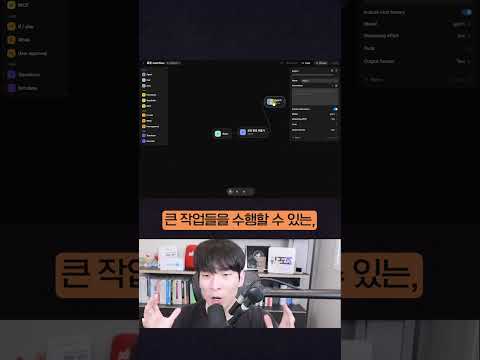
드래그 앤 드롭만으로 만드는 AI 에이전트, OpenAI Agent Builder #shorts
2025. 10. 15.

Bun got bought by Anthropic (yes really)
2025. 12. 3.