- 엘라스틱서치
_analyzeAPI를 사용하여 애널라이저가 텍스트를 토큰으로 어떻게 변환하는지 직접 확인할 수 있습니다. 🔍 GET /_analyze엔드포인트에text와analyzer(예:standard)를 지정하여 특정 애널라이저의 토큰화 결과를 쉽게 디버깅할 수 있습니다. 🛠️standard애널라이저는 공백이나 문장 부호로 단어를 나누는standard토크나이저와 모든 문자를 소문자로 변환하는lowercase필터로 구성됩니다. 🔡- 예시 텍스트 "Apple 2025 MacBook Air 13 M4"는
standard애널라이저를 거쳐 "apple", "2025", "macbook", "air", "13", "m4"와 같이 소문자화되고 공백 기준으로 분리된 토큰으로 변환됩니다. 🍎 - 애널라이저의 구성 요소(캐릭터 필터, 토크나이저, 필터)를
_analyzeAPI에 개별적으로 명시하여 토큰화 과정을 세밀하게 제어하고 분석할 수 있습니다. 🔬 char_filter와filter는 여러 개를 적용하거나 아예 적용하지 않을 수 있지만,tokenizer는 필수적으로 하나만 지정해야 합니다. ⚙️- 애널라이저를 통째로 지정하는 방식과 구성 요소를 개별적으로 명시하는 방식은 동일한 구성일 경우 같은 토큰화 결과를 보여주며, 이는 애널라이저 작동 방식 디버깅에 핵심적입니다. 🔄
- 이
_analyzeAPI는 엘라스틱서치 애널라이저의 동작을 이해하고 문제를 해결하는 데 매우 중요하며 실무에서 자주 활용됩니다. ✅
Recommanded Videos

처음부터 다 아는 사람이 있을까요?
2024. 7. 3.

“사수가 없어서 개발을 잘 하고 있는 건지 모르겠어요…”
2025. 9. 14.
Spring Batch - How to monitor short lived applications? #springbatch #monitoring
2025. 8. 27.
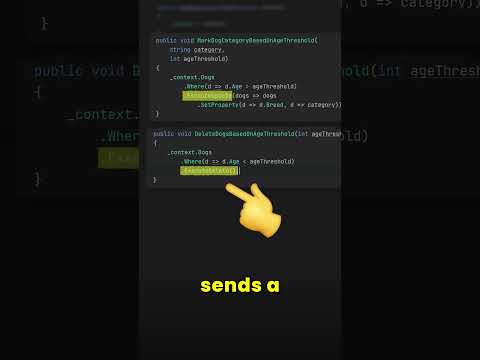
Fast Updates and Deletes in EF Core are awesome
2025. 8. 5.
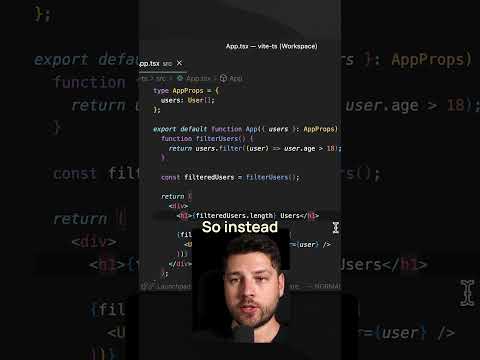
Simple Performance Mistake in React
2024. 9. 12.

Frontend Nation 2024: Cai Cruz - Beyond console.log: Supercharge Your Debugging Skills!
2024. 7. 3.