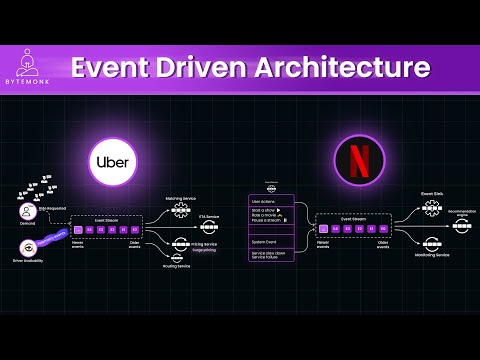
Tracking unique users, hashtags, or events at scale is a massive challenge in big data. HyperLogLog is a probabilistic algorithm that allows companies like Facebook, Google, and Twitter to estimate billions of unique elements while using just a few kilobytes of memory! In this video, we’ll break down HyperLogLog step by step—from basic cardinality counting to the advanced optimizations that make it so efficient. We’ll explore real-world use cases, including its role in web analytics, databases, and distributed systems, and even implement HyperLogLog in code. If you want to master scalable counting techniques and improve your system design knowledge, this is the video for you!
/ bytemonk
📌 Timestamps
00:00 – Introduction: The Counting Problem in Big Data 📊
01:22 – What is Cardinality & Why It Matters in Large-Scale Systems
03:55 – Simple Counting vs Probabilistic Counting 🔢
12:12 – Understanding LogLog: How It Estimates Unique Elements
12:40 – HyperLogLog: The Evolution of LogLog for Higher Accuracy
14:42 – Real-World Use Cases: How Facebook, Google & Twitter Use It 🌍
14:55 – Code Implementation: How to Apply HyperLogLog in Practice
• System Design Interview Basics
• System Design Questions
• LLM
• Machine Learning Basics
• Microservices
• Emerging Tech
AWS Certification:
AWS Certified Cloud Practioner: • How to Pass AWS Certified Cloud Practition...
AWS Certified Solution Architect Associate: • How to Pass AWS Certified Solution Archite...
AWS Certified Solution Architect Professional: • How to Pass AWS Certified Solution Archite...
🔗 References:
Facebook Engineering on HyperLogLog
https://engineering.fb.com/2018/12/13...
#hyperloglog #systemdesign #distributedsystems #bigdata


![[10분 테코톡] 아이나의 서킷브레이커](https://i1.ytimg.com/vi/lddAZUvOUrs/hqdefault.jpg)