- AI 에이전트의 핵심 패턴: 내부 지식(핸드북)과 실시간 웹 검색(특정 URL 또는 광범위한 검색)을 결합하여 사용자 질의에 응답하는 AI 에이전트 구축 패턴을 소개합니다. 🧠
- 에이전트 의사결정: 에이전트는 사용자 질의에 따라 내부 정책, 특정 URL 검색, 또는 도메인 필터링이 적용된 광범위한 웹 검색 중 어떤 도구를 사용할지 지능적으로 결정합니다. 🎯
- 단일 웹페이지 정보 추출:
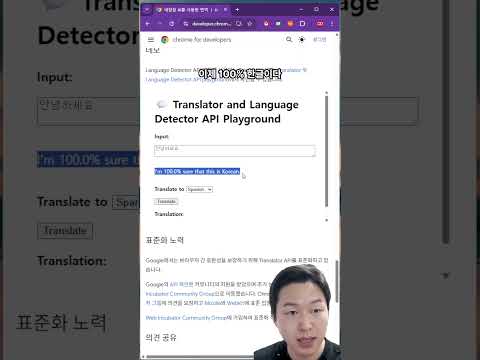
dockling라이브러리를 사용하여 특정 URL의 HTML 콘텐츠를 LLM이 이해할 수 있는 마크다운 형식으로 변환하고 요약합니다. 📄 - 광범위한 웹 검색 기능: OpenAI의 내장 웹 검색 도구를 활용하여 특정 도메인으로 검색을 제한하고, 답변과 함께 출처(citations)를 구조화된 형식으로 제공합니다. 🌐
- 내부 지식 활용: 마크다운 형식의 핸드북과 같은 내부 문서를 에이전트의 도구로 정의하여, 필요할 때만 해당 정보를 검색하고 답변에 활용합니다. 📚
- 구조화된 출력 및 인용: Pydantic 모델을 사용하여 에이전트의 응답(답변 및 인용)을 명확하고 타입-세이프하게 구조화하여 사용자에게 신뢰성 있는 정보를 제공합니다. 🏗️
- 모델 선택의 중요성: 빠른 응답을 위해 GPT-4.1 nano와 같은 비추론 모델을 사용하거나, 더 깊은 이해와 복잡한 검색을 위해 GPT-5 nano와 같은 추론 모델을 선택할 수 있습니다. ⚡
- 재사용 가능한 구성 요소: 제시된 모든 구성 요소와 패턴은 다양한 AI 에이전트 구축 프로젝트에서 쉽게 재사용할 수 있도록 설계되었습니다. 🛠️
Recommanded Videos