All Machine Learning Beginner Mistakes explained in 17 Min
#########################################
I just started my own Patreon, in case you want to support!
Patreon Link: / infinitecodes
#########################################
Don’t make the same mistakes I made! Here is a list of things to avoid when starting Machine Learning and Data Science.
Also Watch:
Learn Machine Learning Like a GENIUS and Not Waste Time • Learn Machine Learning Like a GENIUS and N...
All Machine Learning Concepts Explained in 22 Minutes • All Machine Learning Concepts Explained in...
All Machine Learning algorithms explained in 17 min • All Machine Learning algorithms explained ...
The Math that make Machine Learning easy (and how you can learn it) • How Math makes Machine Learning easy (and ...
15 Machine Learning Lessons I Wish I Knew Earlier • 15 Machine Learning Lessons I Wish I Knew ...
Machine Learning Playlist: • How Math makes Machine Learning easy (and ...
Git/Github Playlist:
• How to clone GitHub Repository (2024 updated)
================== Timestamps ================
00:00 - Intro
Data-Related Issues
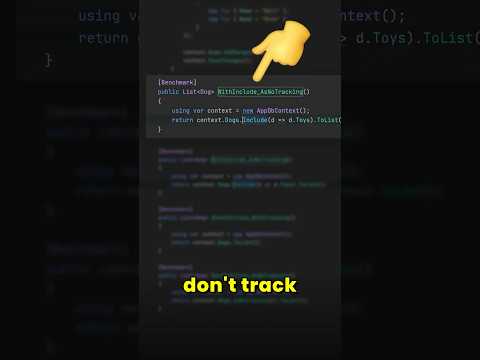
00:36 - Not cleaning your data properly
01:20 - Forgetting to normalize/standardize
01:59 - Data leakage
02:38 - Class imbalance issues
03:17 - Not handling missing values correctly
Model Training
04:03 - Using wrong metrics
04:55 - Overfitting/underfitting
05:38 - Wrong learning rate
06:08 - Poor hyperparameter choices
06:58 - Not using cross-validation
Implementation
07:29 - Train/test set contamination
08:25 - Wrong loss function
08:58 - Incorrect feature encoding
09:54 - Not shuffling data
10:19 - Memory management issues
Evaluation
10:40 - Not checking for bias
11:12 - Ignoring model assumptions
12:05 - Poor validation strategy
12:31 - Misinterpreting results
Common Pitfalls
13:43 - Using complex models too early
14:52 - Not understanding the baseline
15:47 - Ignoring domain knowledge
16:46 - Poor documentation
17:15 - Not version controlling



![[2025 마지막 영상] 서버보다 회사가 먼저 터질 뻔했던 한 해를 돌아보다 (feat. 뚜기의 첫크)"](https://i2.ytimg.com/vi/mdOjbQpPJ0o/hqdefault.jpg)