- DeepSeek-R1: 오픈소스 추론 모델 출시 🎉
- RL 기반 학습 전략: 체인 오브 스토리(Chain of Thought) 활용 🧠
- 다단계 학습 과정: 미세 조정, 강화 학습, 추가 미세 조정의 3단계 ⚙️
- 144,000개의 수학 및 코딩 문제를 활용한 강화 학습 🔢
- 고품질 추론 결과 필터링 및 재학습: 일반적인 능력 향상 ⬆️
- 다양한 보상 함수 활용: 추론 능력과 유용성, 무해성 모두 고려 💯
Recommanded Videos
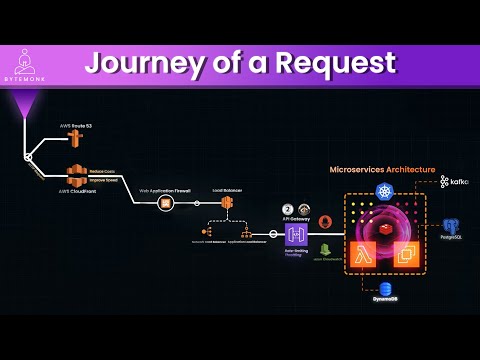
Web Application Architecture: Full Request-Response Lifecycle
2024. 10. 22.
This AI System Finds Amazon's Top Products on AUTOPILOT (No-Code n8n Tutorial)
2025. 7. 18.

Claude's NEW Data Analysis Update! (Insane Results)
2024. 10. 26.

Memory Safety in Rust #rustlang #rust #rustprogramming #programming
2024. 10. 8.

상위 1% 유저만 아는 멘션 기능
2024. 7. 29.

Unity Watch Party - Independent Games Festival Awards | GDC 2025
2025. 3. 10.