카
카카오
April 18, 20251회
Iceberg Operation Journey: Takeaways for DB & Server Logs
간단 소개
Iceberg 테이블에 DB 로그와 서버 로그를 효율적으로 관리하기 위한 운영 전략, 파티셔닝, 최적화 방법, 모니터링에 대한 여정을 공유합니다.
AI Summary
- 로그 유형 및 수집 방법
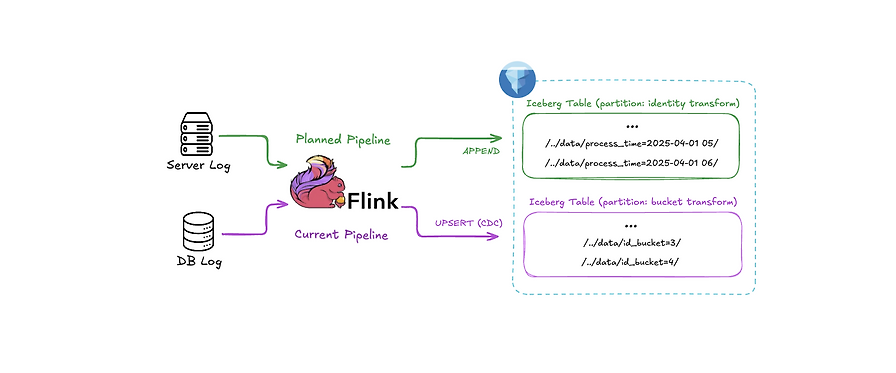
- DB 로그는 Apache Flink를 사용하여 MySQL 테이블의 변경 사항을 Iceberg 테이블로 동기화합니다. UPSERT 모드를 사용하고, Primary Key 기반의 버킷 변환 파티셔닝을 적용하여 쿼리 성능을 최적화합니다.
- 서버 로그는 Apache Kafka를 통해 수집되며, Flink를 사용하여 ORC 형식으로 저장됩니다. APPEND 모드를 사용하여 Iceberg에 로드하는 것을 고려 중이며, 시간별 파티셔닝 및 최적화 기능을 통해 작은 파일 문제를 해결하고자 합니다.
- 압축, 파티셔닝 및 최적화 전략
- Iceberg의 기본 파일 형식은 Parquet이며, zstd 압축 코덱을 사용합니다. 다양한 압축 수준을 테스트한 결과, CPU 사용량은 증가하지만 전체 성능에 미치는 영향은 미미했습니다. 파일 크기 감소 효과는 Parquet 형식과 zstd 코덱 사용에서 비롯됩니다.
- DB 로그는 UPSERT 모드, 버킷 변환 파티셔닝을 사용하고, 서버 로그는 APPEND 모드, identity 변환 파티셔닝을 사용합니다. Compaction, Snapshot Expiration, Delete Orphan Files 등의 최적화 기능을 활용하여 데이터 관리 효율성을 높입니다.
- 모니터링
- Iceberg 테이블의 상태를 지속적으로 모니터링하여 작은 파일 관리, 파티션 설정, 최적화 작업 실행 여부를 확인합니다. Trino의 $files 테이블 또는 Spark SQL의 tablename.files 메타데이터 테이블을 사용하여 파일 상태를 모니터링하고, Prometheus, Grafana, TSCoke를 사용하여 시각화합니다.
Next Feeds

Firehose부터 OpenSearch까지: AWS 서비스를 활용한 로그 분리 전략
AWS 서비스를 활용하여 특정 로그를 분리하고 장기간 보관하는 다양한 전략을 제시합니다. MDC, Fluent Bit, Lambda 등을 활용한 방법을 설명합니다.
로그 분리AWSOpenSearchFirehoseLambda
2025. 4. 17.
펫프렌즈
Cursor와 TDD로 만드는 Swift Macro
Cursor와 TDD를 활용하여 Swift Macro를 개발하는 과정과 LLM을 활용했을 때의 장점을 설명하고, 실제 프로덕션에 적용 가능한 신뢰도 높은 코드를 작성하는 방법을 제시한다.
Swift MacroTDDCursorLLMSwiftSyntax
2025. 4. 17.
당근

🛒 토스 쇼핑 추천 시스템: 수백만 사용자와 상품을 잇는 멀티 스테이지 접근법
토스 쇼핑은 멀티 스테이지 추천 시스템을 통해 사용자 맞춤형 상품을 추천하고, ML Engineer를 채용 중이다.
추천 시스템멀티 스테이지RetrievalRankingRe-ranking
2025. 4. 17.
토스

Amazon FSx 파일 시스템 선택 및 DR 가이드
Amazon FSx 파일 시스템의 종류, 특징, 그리고 DataSync를 활용한 HA 및 DR 구성 방안을 소개합니다.
Amazon FSxDataSyncHADR파일 시스템
2025. 4. 17.
베스핀글로벌

AI야, 문서 좀 대신 써 줘 - 1. 일단 시작!
카카오 기술 블로그에서 AI를 활용한 기술 문서 자동화 프로젝트 'TW 에이전트' 개발 여정을 시작합니다.
AI기술 문서자동화TW 에이전트카카오
2025. 4. 17.
카카오
UX 라이팅, 이름을 불러주다: 직무의 가시화와 중요성
UX 라이팅의 정의, 중요성, 국내 발전 과정 및 과제를 분석하고, UX 라이팅의 가치 인식 개선 필요성을 강조합니다.
UX 라이팅UX 라이터사용자 경험직무 정의가치 인식
2025. 4. 16.
현대자동차