AWS
자비스앤빌런즈의 Amazon DynamoDB 도입기 – 외부 연계 데이터 저장과 약관 서비스 개선

자비스앤빌런즈는 삼쩜삼 서비스의 트래픽 부하 문제를 해결하기 위해 Aurora MySQL에서 Amazon DynamoDB와 S3로 전환하여 외부 연계 데이터 저장 및 약관 서비스를 개선하고 성능, 확장성, 운영 효율성을 확보했습니다.
자비스앤빌런즈는 세금 신고·환급 서비스 '삼쩜삼'의 특정 시기 트래픽 집중으로 인한 RDBMS(Aurora MySQL) 부하 문제를 해결하기 위해 AWS DCAD 워크샵을 통해 Amazon DynamoDB와 Amazon S3를 도입했습니다.
-
외부 연계 데이터 저장 서비스 개선
- 월 수억 건의 외부 연계 데이터 저장 시 Aurora MySQL의 I/O 부하, 스토리지 비용, 이진 로그 동기화 지연 문제 발생.
- 메타 정보는 DynamoDB, 대용량 JSON 데이터는 S3에 저장하는 구조로 변경하여 성능 유지 및 확장성 확보.
- 향후 Aurora MySQL 테이블 정리 및 S3 저장 방식 개선을 통해 추가 비용 최적화 가능성 확인.
-
약관 서비스 개선
- 사용자별 알림 수신 동의 기능 이전을 위해 읽기 중심 패턴, 빠른 조회, 확장성, 운영 효율성을 고려하여 DynamoDB를 선택.
- API 연계 및 데이터 동기화 방식의 한계를 극복하고, Aurora MySQL 읽기 부하 30-40% 감소, 메시지 처리 속도 최대 5배 개선, 전송 실패율 약 70% 감소 달성.
-
서비스 운영 관점 주요 포인트
- 매년 5월 트래픽 집중을 대비하여 Warm throughput을 사전 조정하여 안정적인 처리량 확보.
- 백오피스 운영 효율화를 위해 **GSI(Global Secondary Index)**와 **희소 인덱스(Sparse index)**를 활용하여 다양한 조건의 데이터 조회 가능.
Next Feeds
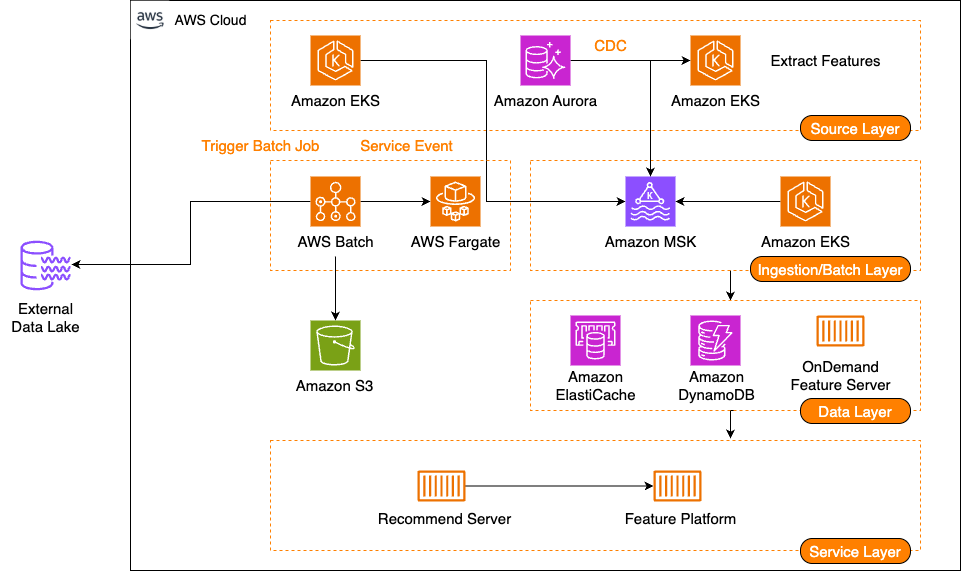
당근의 AWS 기반 피처 플랫폼 구축 여정, Part 2: 피처 수집
당근은 AWS 기반 피처 플랫폼의 스트림 및 배치 수집 파이프라인을 구축하여 추천 시스템을 고도화하고 비용을 절감했다.

당근의 AWS 기반 피처 플랫폼 구축 여정, Part 1: 구축 배경과 피처 서빙
당근이 추천 시스템 고도화를 위해 AWS 기반 피처 플랫폼을 구축하고, Multi-level cache를 활용한 피처 서빙 아키텍처와 최적화 전략을 설명합니다.
Tech Topic 기술블로그 개선 실험 - 콘텐트, 성능, SEO, AEO
SK플래닛 Tech Topic 기술블로그가 콘텐트, 성능, SEO, AEO 개선 실험을 통해 방문자 수를 크게 늘린 사례를 공유합니다.

AI뒤에 사람 있어요: Human-in-the-loop를 위한 VLMOps 어드민 구축기
무신사가 AI의 한계를 보완하고 서비스 최적화를 위해 Human-in-the-loop 기반 VLMOps 어드민을 구축하여 AI 검증 및 운영 효율을 크게 향상시킨 사례.
AI뒤에 사람 있어요: Human-in-the-loop를 위한 VLMOps 어드민 구축기
무신사가 AI 모델의 한계를 보완하고 서비스 최적화를 위해 Human-in-the-loop 기반 VLMOps 어드민을 구축하여 데이터 검증 및 운영 효율을 크게 향상시킨 사례입니다.

제1회 리멤버 사내 해커톤을 마치며
리멤버가 AWS와 함께 'Gen AI 해커톤'을 성공적으로 개최하고, 참가자들의 열정과 아이디어에 감탄하며 AI 여정의 시작을 알린 후기.