Recommanded Videos
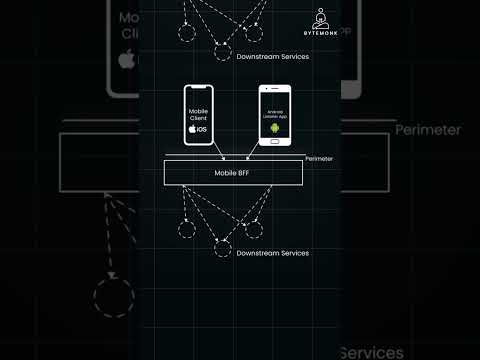
Types of BFF Patterns in Microservices
2024. 9. 23.

How to land your dream software engineering internship
2025. 4. 30.

Into the Wckd Masterminds of AI💥 OpenAI Technical Goals 💥
2024. 9. 18.

Amazon DynamoDB - Paper Explained
2024. 9. 28.

The Simplest Way to Automate Scraping Anything with No Code (Apify + n8n tutorial)
2025. 5. 16.

Grok-2 (Fully Tested) : The BEST & UNCENSORED MODEL is here? (Beats Claude-3.5 Sonnet, GPT-4O!?)
2024. 8. 16.