버
버즈빌
July 31, 20181회
How we pipe data
간단 소개
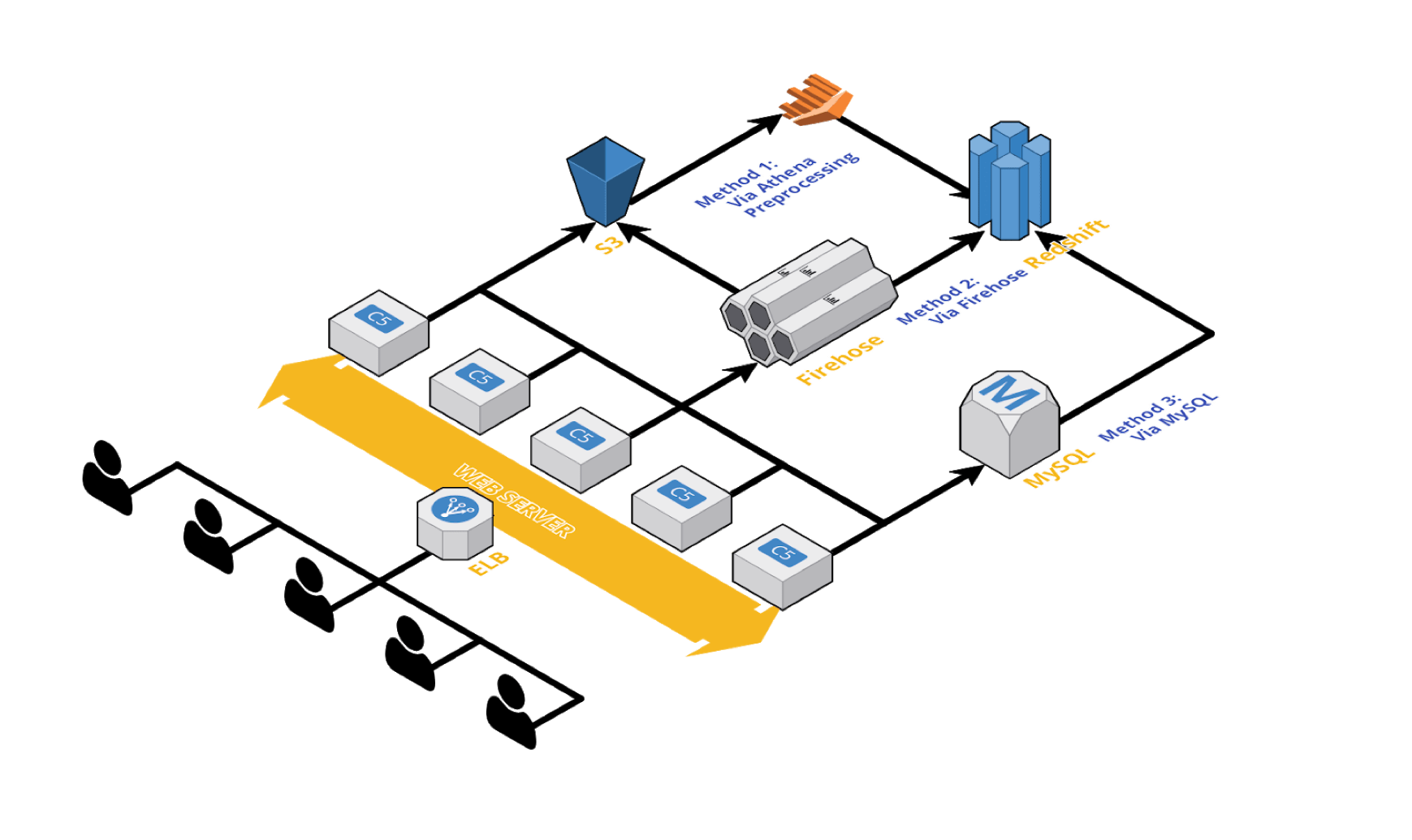
버즈빌은 Athena, Firehose, MySQL Asynchronous Loads를 활용하여 데이터 파이프라인을 구축하고 Redshift에 데이터를 통합합니다.
AI Summary
- 데이터 파이프라인 구축 배경
- 버즈빌은 다양한 소스에서 발생하는 데이터를 분석하기 위해 데이터 파이프라인 구축 필요성을 느낌.
- Redshift를 데이터 스토리지로 선택, 여러 AWS 서비스와 연동 용이.
- 데이터 수집 및 전송 방법
- Athena: 전처리 필요한 대용량 데이터 처리, S3 데이터 가공 후 Redshift로 전송. 서버 관리 불필요, 비용 효율적.
- Firehose: Fluentd와 연동, 안정적인 데이터 전송 파이프라인 구축. 스키마 자동 변경 불가.
- MySQL Asynchronous Loads: RDS MySQL DB 데이터 복제, FULL_COPY, INCREMENTAL_COPY, UPDATE_LATEST_COPY 방식 활용. 데이터 특징에 맞게 조정 필요.
- 데이터 파이프라인 활용 및 고려사항
- 데이터 분석 환경 구축을 위해 3가지 방법을 조합.
- 데이터 종류에 따라 적절한 전송 방법 선택 (Transactional log vs Fact table).
- BD 매니저, 애널리스트들이 데이터 분석을 쉽게 할 수 있는 환경 구축 목표.
Next Feeds

A/B Testing - Sampling부터 Interpretation까지
A/B 테스팅의 샘플링 방법과 결과 해석에 대한 실질적인 가이드라인을 제시하고, 흔히 발생하는 문제점과 해결 방안을 공유합니다.
A/B testing샘플링t-test랜덤 샘플링결과 해석
2018. 6. 14.
버즈빌

Apache Spark에서 컬럼 기반 저장 포맷 Parquet(파케이) 제대로 활용하기
Apache Spark에서 Parquet 포맷을 활용하여 저장 용량과 처리 성능을 극적으로 개선한 경험 공유 및 최적화 과정 분석.
Apache SparkParquet컬럼 기반 저장데이터 최적화성능 향상
2018. 5. 24.
VCNC

버즈빌의 AWS Summit 2018 발표 참관기
버즈빌, AWS Summit 2018에서 Kubernetes 활용 경험을 공유. Kubernetes 도입 배경, 기능 소개, AWS 환경에서의 활용 데모를 통해 서비스 운영의 안정성을 강조.
AWS SummitKubernetesContainer OrchestrationkopsDevops
2018. 5. 4.
버즈빌

Go 서버 개발하기
Django 기반 서버의 성능 개선을 위해 Go 언어를 도입하고, Docker, Nginx를 활용하여 효율적인 인프라를 구축한 경험 공유.
GoDjangoDockerNginxAPI
2018. 2. 12.
버즈빌

비트윈 데이터팀의 Spark Summit EU 2017 참가기
비트윈 데이터팀의 Spark Summit EU 2017 참가 후기: Spark의 발전 방향, 딥러닝 지원, 컨퍼런스 경험 공유.
Spark빅데이터딥러닝컨퍼런스데이터 분석
2017. 12. 18.
VCNC

아마존 에코를 활용한 음성 인식 에어컨 제어
아마존 에코와 라즈베리파이를 이용, 음성으로 에어컨을 제어하는 시스템 개발 과정과 회로 설계, LIRC 설정, 프로토콜 분석을 설명합니다.
아마존 에코라즈베리파이음성 인식에어컨 제어LIRC
2017. 9. 27.
버즈빌