S
skplanet
October 23, 20241회
Spark Streaming을 활용한 파생 데이터 생성 시간 감축 사례
간단 소개
Spark Streaming을 활용하여 파생 데이터 생성 시간을 단축하고 실시간 데이터 처리 시스템을 구축한 사례를 소개합니다.
AI Summary
- 파생 데이터 생성 방식의 문제점
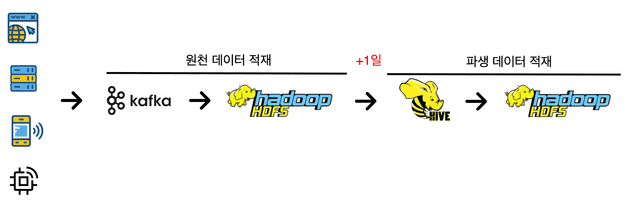
- 기존 Hive Query 기반 배치 작업은 데이터 완전성을 위해 +1일 이후에 파생 데이터를 생성하여 분석 지연 발생
- 실시간 데이터 처리의 필요성 증대
- SPaaS 'Router' 서비스 개발
- 데이터 파이프라인 시각화, Hive Query 재사용, 리소스 조정, 다양한 저장소 지원, 모니터링 기능 제공
- Kafka Connect 기반 데이터 저장 기능(Connect)과 Spark Streaming 기반 데이터 변환 기능(Processor)으로 구성
- Stream-Processor를 통한 실시간 데이터 변환
- Spark Streaming을 사용하여 Kafka 데이터를 실시간으로 처리하고 Hive Query를 재사용
- Yarn 클러스터 자원 활용, 파이프라인별 리소스 할당, 데이터 처리량 조절 기능 제공
- Spark Job 정상 수행 여부, 처리 데이터 수, Kafka 데이터 지연 여부 등 3가지 관점에서 모니터링
Next Feeds
[#1 LLM Tutorial With RAG] 나만의 Chat GPT를 만들어봅시다!
RAG 기술을 활용하여 LLM의 한계를 극복하고, 나만의 Chat GPT를 만드는 튜토리얼을 소개합니다.
LLMRAGChat GPTLangChainOllama
2024. 10. 22.
현대자동차

멀티 테넌트 데이터를 격리하고 더 안전하게 만드는 방법
멀티 테넌트 환경에서 데이터 격리 수준을 높이고 보안을 강화하는 방법과 고려 사항을 제시합니다.
멀티 테넌트데이터 격리테넌트 ID암호화보안
2024. 10. 21.
NHN

협업 필터링을 넘어서: 하이퍼커넥트 AI의 추천 모델링
something wrong
2024. 10. 21.
하이퍼커넥트

ELK 환경에서 좀 더 정교한 이슈 트래킹 Part2 - Thread Context 적극 활용하기
ELK 환경에서 Thread Context를 활용하여 이슈 트래킹을 개선하고, 로그 분석 효율성을 높이는 방법을 제시합니다.
ELKThread ContextSentryMDCRequestId
2024. 10. 17.
카카오페이

올리브영 물류시스템에서는 데이터를 어떻게 주고 받을까?
올리브영이 EAI에서 MQ로 데이터 전송 방식을 변경하여 실시간 전송, 대용량 데이터 처리, 시스템 안정성 측면에서 성능을 개선했습니다.
올리브영물류시스템EAIMQ데이터 전송
2024. 10. 17.
올리브영
자율주행 연구원이 바라본 2024 CVPR
2024 CVPR 참관 후기: 자율주행 관련 회사들의 기술 동향, 워크샵 내용, 부스 참관 후기를 통해 자율주행 기술의 발전 방향을 조망한다.
자율주행CVPR센서 퓨전End-to-EndFoundation Model
2024. 10. 17.
현대자동차